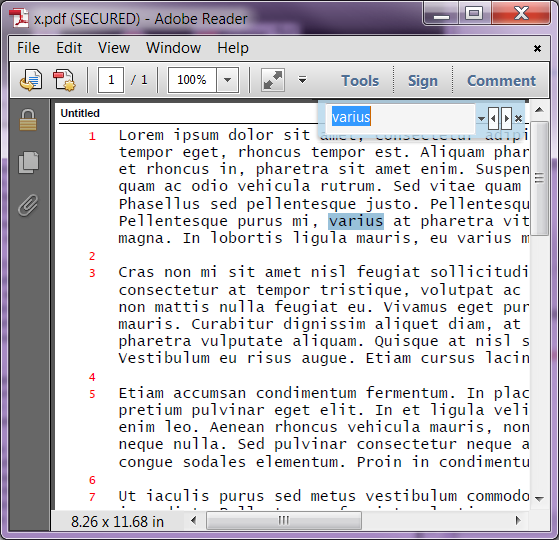
OCR
Click here to watch a video tutorial.
Scanned pages can be converted to searchable text that will be stored invisibly within the PDF when saved. This allows readers of the PDF to search the PDF for the text, and also to copy and paste the converted text. pdfMachine uses optical character recognition (OCR) technology to convert the scanned pages into text. Conversion to text by OCR is not 100% accurate.
OCR can be performed :
- Automatically from pdfScanMachine after a page has been scanned. Shown in this video.
- On images/scanned pages in a PDF from the pdfMachine Viewer menu.
- On images/scanned pages in existing PDFs from the command line, with no user input. This allows OCR to be performed in batches.
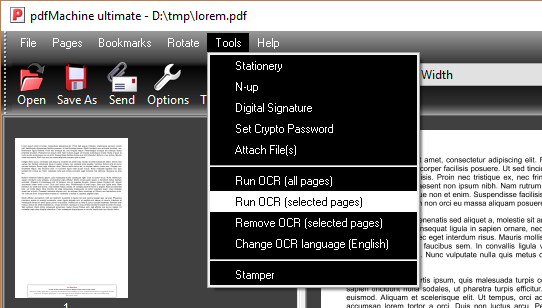
To convert a scanned page into text first open it in pdfMachine. You can use pdfScanMachine to scan a page into pdfMachine. OCR can even be done during the scanning process by checking the OCR checkbox on the scan dialog. You can OCR any page from the Tools menu in pdfMachine. In either Viewer mode or Edit mode select "Run OCR (all pages)" to perform OCR on all pages.
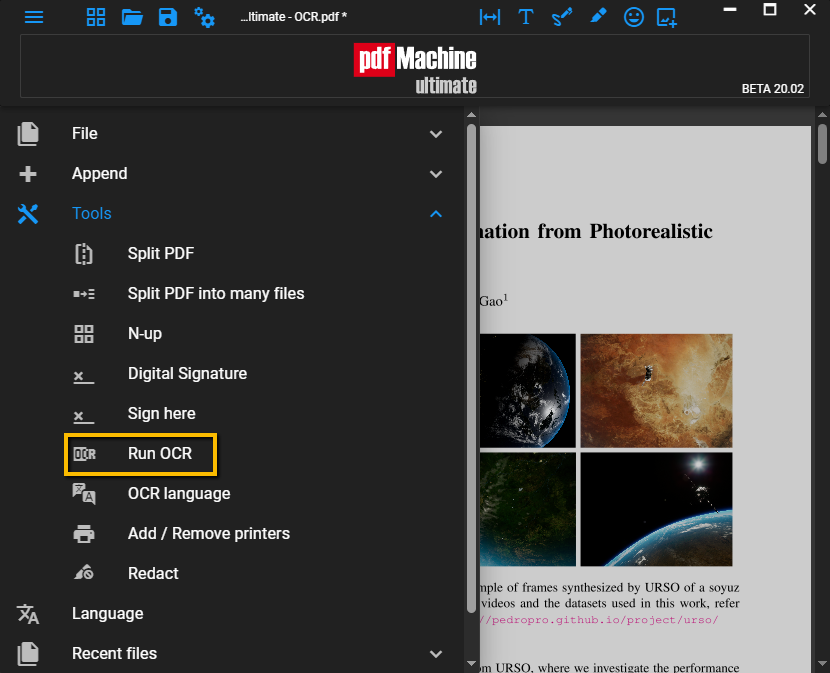
From the Edit window you can select pages and then "Run OCR (selected pages)" to perform OCR on some of the pages. OCR can take awhile, so if you there are only a few pages that need OCR then you should only OCR those selected pages. You can also use the Remove OCR menu item to remove pdfMachine generated OCR from selected pages. You may wish to do this if you have a page which is a poor quality scan and has not converted to OCR well.
The very first time you run OCR from pdfMachine you will need to select the language of the file you are converting from. For example, if your scanned page has English text on it select "English". pdfMachine will proceed to download and install the language files needed to perform the conversion.
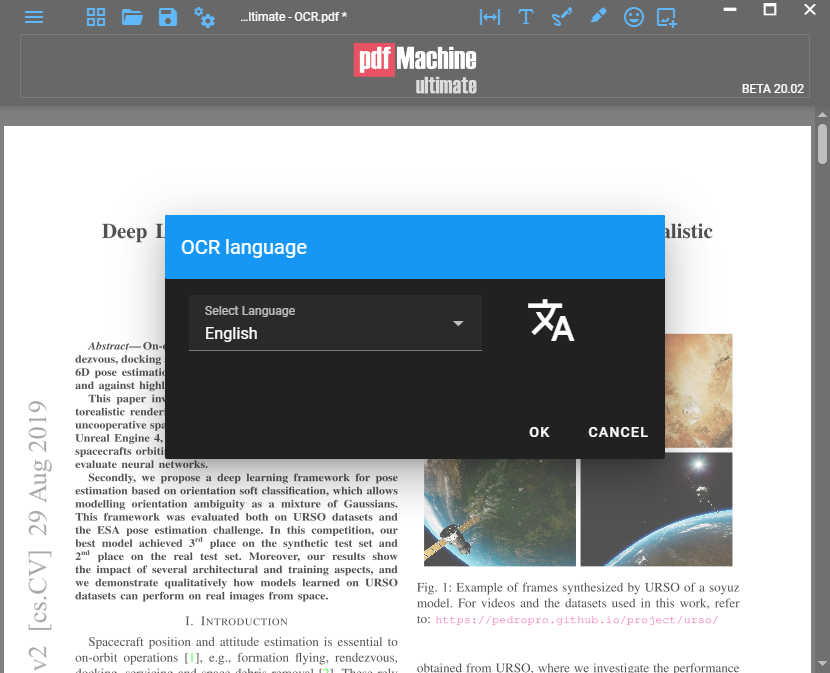
note: The language selection will be remembered for future conversions. The language files do not need to be downloaded each time. If you wish to change the language you can do this using the "Change OCR language" from the Tools menu.
pdfMachine will then convert the scanned pages.
Perform a Save or Save As to save the invisible text with the PDF.
The text is now searchable from PDF readers with search capability. The text can also be copied and pasted.